Solved
Redundant data in dataset.
Hi,
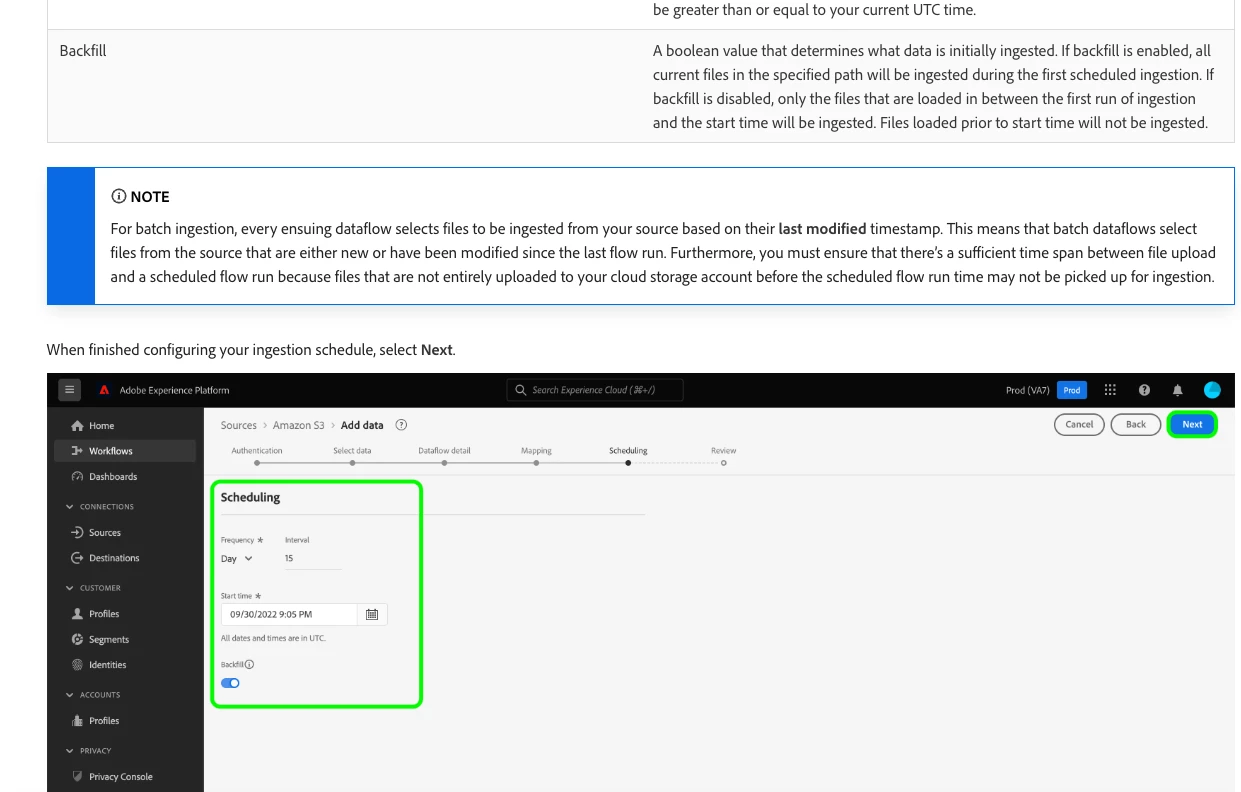
I am ingesting some data from Amazon S3 bucket every 15 mins and i noticed that the data which is already ingested is getting ingested again and again as a separate row in the dataset.
Is there a way to make sure that data already ingested is not ingested again?