
Adobe Experience Platform’s Streaming Sources and Destinations Overview and Architecture
Authors: Mandeep Gandhi, Som Satpathy, and Harry S.

Adobe recently announced two new Streaming Sources and Destinations as part of its real-time customer data platform offering: Azure Event Hub and AWS Kinesis. This blog will detail the use cases, how we started, what technical decisions we took, and the challenges we faced while executing this release.
Adobe Experience Platform has a large Kafka infrastructure with multiple environments and data centers. We had already built Pipeline Smarts for stream processing. It made perfect sense for us to explore Kafka Connect for our Ingress/Egress story. We got this opportunity in our Adobe Experience Platform Hack-week last December. During our Hack-Week in December 2019, we built a powerful proof of concept that included filters on attributes of data, SMTs, and how to ingress/egress.
Development
Common DSL
We set on the quest of what would it take to get Kafka Connect production-ready. The idea was not just to build a couple of connectors and get them working rather build such a framework where we can add more connectors at scale either OOTB or our custom connector(s). An enterprise does not choose a technology easily, but when it does, it places big bets on that technology. So we started with the most important things: performance and scale. We did extensive performance testing of some uncomplicated connectors that we built. We soon realized that to meet the performance requirements, we would have to batch the messages (prior experience also helped :)). There were too many variables to play along — the number of messages to batch, size, time to wait, etc. Also, throughput and latency performance depends on machine specs, cluster connectivity, etc. We built an Abstract layer so that essentially re-use these settings once we came up with a sweet spot of throughput and latency we could:
- Apply the same set of configurations to any new connector we add via this framework.
- Abstract error handling/ validation logic, business telemetry collection.
- Inject any traceability/ monitoring aspects.
Performance
Here are some performance results that we gathered from batching and trying out different configurations:
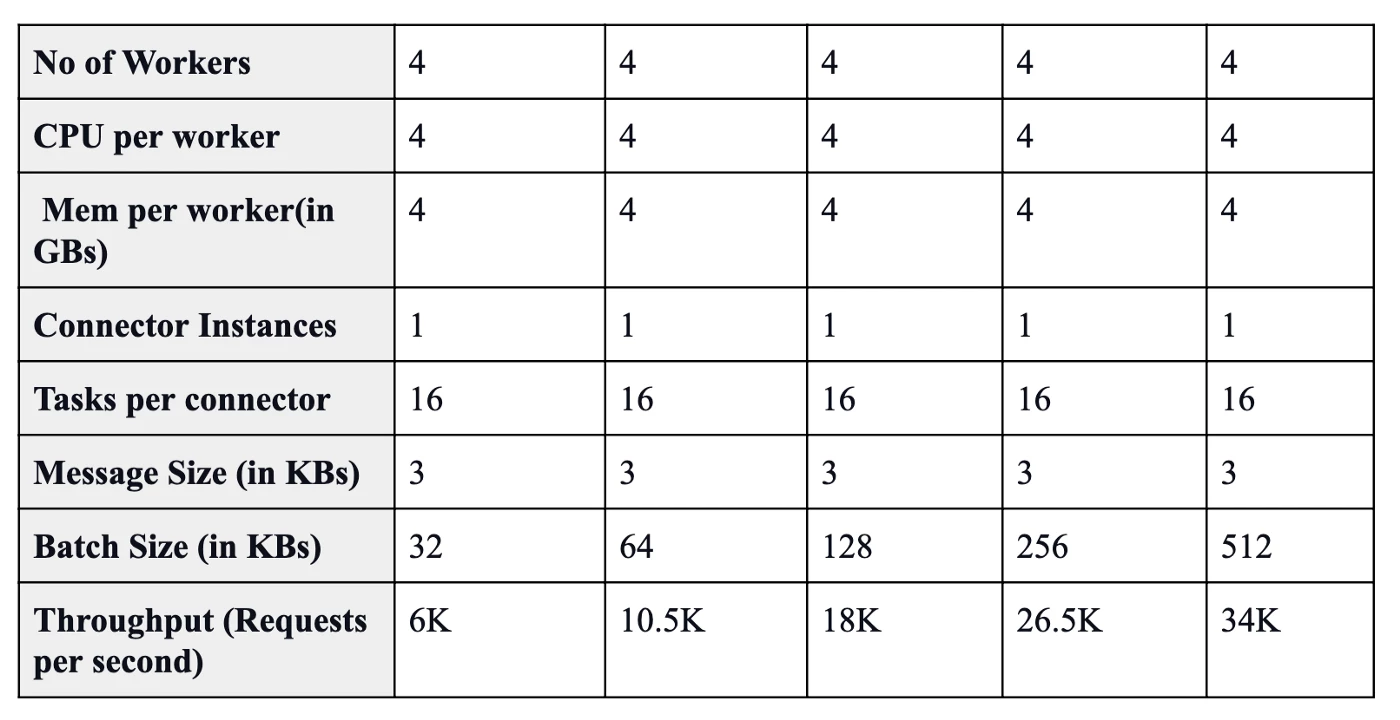
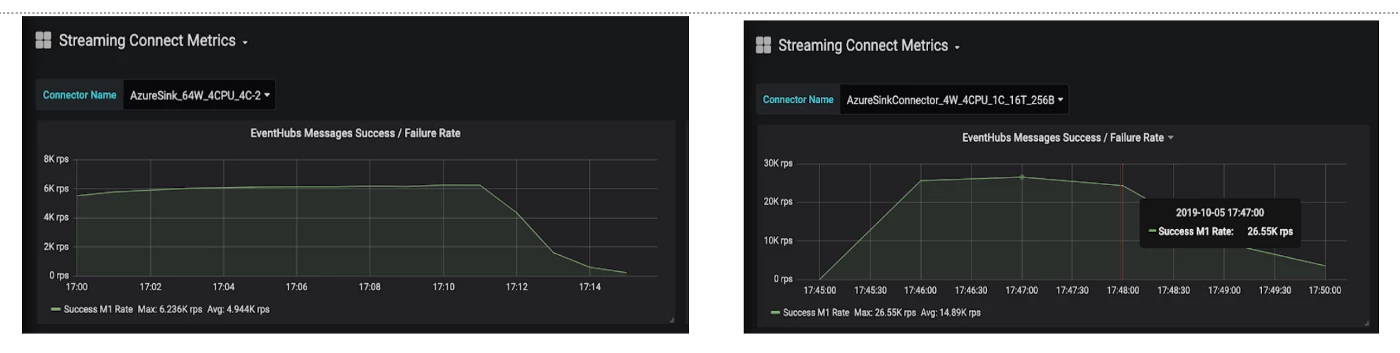
Eventually, we realized that even this is not enough to be performant and efficient* enough, details for which will be shared in our next blog.
Resiliency
Next was to build resilience in the connectors. The options available from Kafka Connect were:
- Tolerance Settings for malformed messages
- Throwing RetriableException and setting an appropriate retry timeout (via "errors.retry.delay.max.ms" and "errors.retry.timeout").
"Failing fast to learn fast" is a great engineering principle and we can leverage some of Kafka Connect's constructs to make sure that we fail fast if we are not able to instantiate any new connector. We leveraged the validate method of the connector and chose to fail if we found that we could not perform the real task of getting/putting data with the current environment setting and config passed in the connector.
There is a bit more work required apart from the validation and fail fast implementation. For message retries (due to network or connection failures) to work, the connectors are expected to keep some sort of delivery count and buffer of the message to be delivered. We can co-relate it with how the TCP automaton works. We send a batch of messages and mark them as sent; at the same time start a timer. You wait for acknowledgment of the messages. If they are delivered, you remove them from the buffer with the next set of messages. If they fail, appropriate action is taken based on the type of error (system error or business error). If the timer ticks out of time, we increase the retry count and re-send the messages.
Next came the part where we needed to integrate the Kafka Connect framework to solve the business use cases. Those use cases required logic for filtering, validating parts of messages, and even doing some little transformations here and there. For that Kafka Connect provides transforms. You can use OOTB ones or create new transforms to handle the transformations you want. We could also chain such transformations by using the configurations which we provide while instantiating the connectors. We implemented a few transformations for filtering, JSON-Patching using this JSON Patch Library. We already had vetted this library in terms of performance while we were developing Pipeline Smarts.
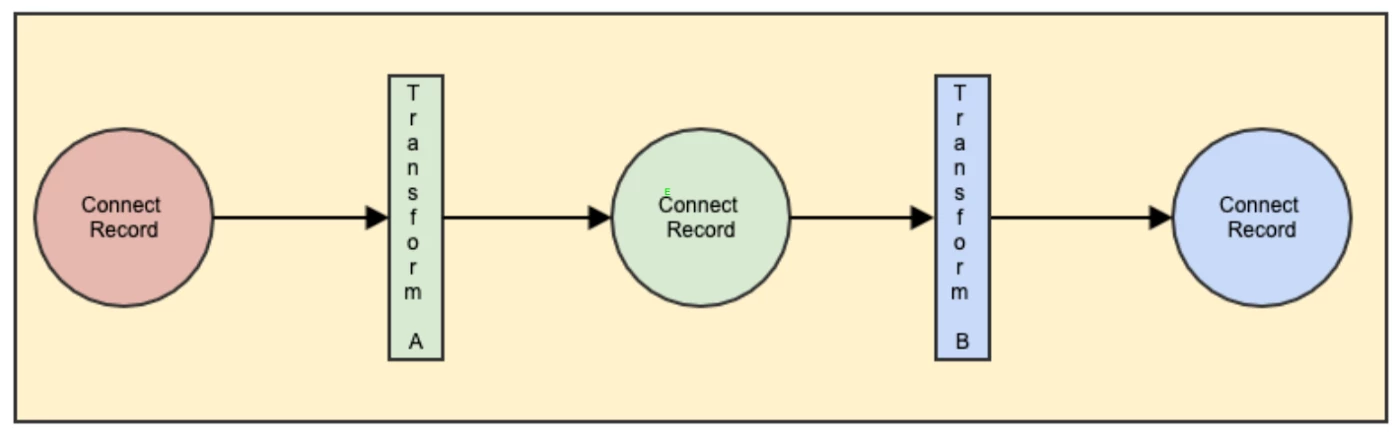
Given that we have gone through development bits, let's now explore what it entails to call Kafka Connect production-ready.
Operational Readiness
Monitoring
So continuing the story. Our system works. We see the logs with all messages showing success. And that's what we would show to our customers, no? 😉
To bring some insights into the system, you would need some metrics to show how our system and application (connector) is performing where you measure the throughput and latency. We also chose to set some alerts over some of the metrics. One straightforward solution is to get the metrics up and running with Prometheus and Grafana. Kafka provides a bunch of JMX metrics. Some of the interesting ones are regarding failure and message delivery times.
You might need to spit some metrics out if you have done special handling for batching and error handling to track your latency and performance numbers as we did.
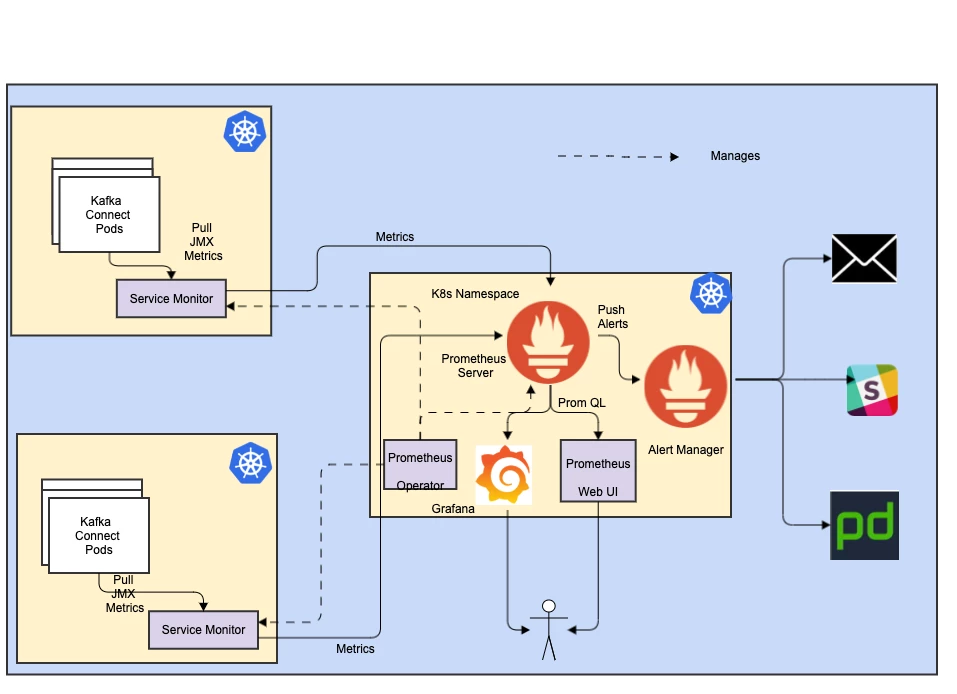
Security
Every platform, particularly with an open core that leverages open source technology like Kafka, must have security designed into the architecture and solution.
The following security knobs were turned on for Production environment:
- Enabling SSL on the rest endpoint, workers, and connectors.
- Adding authentication for Rest endpoints, and authentication for brokers: Kafka Connect Rest framework has only support for Basic Authentication for now. But if we want to extend this with our custom implementation ( Oauth, token-based, etc), we can leverage Kafka Connect Rest Extension and implement a filter (public class OAuthFilter implements ContainerRequestFilter) which will help us filter the request (public void filter(ContainerRequestContext requestContext)) based on the security requirements.
- Handling Secrets- We can externalize secrets using this KIP. This is so much required when we are dealing with any cloud-based offering when we need to pass credentials to the connector for validation and instantiating.
Health Checks
If we wish to check the health of your workers you can also use Kafka Rest Extension ( the one we used for custom authentication) to expose a health endpoint (a rest endpoint), which can essentially check on the health of any dependent service. This is great for if you are running containerized workers (on K8s/ DCOS etc).
Challenges and Troubleshooting
connectors stuck in rebalance loops? Or encountered weird setup problems and wondering how the heck are others using and praising this technology? If yes, then you might need to pay attention to these configurations very carefully:
Internal Topics: There are 3 internal topics that Connect uses:
- Config Topic: Must have a single partition, regular replication (3 might be enough). ( If you don't use a single partition, you get rebalance loops)
- Status Topic: Multiple partitions, regular replication.
- Offset Topic: High partitions recommended with regular replications. (Offset topic is only used by producers to store the offset of the committed messages so you can decide the number of partitions according to the source connectors you are expected to deploy and run).
Finally, Connect Group ID must be unique across Kafka Connect Clusters (typically the same set of brokers) f. If you try to re-use the same id (which is "kafka-connect" by default), you will start getting rebalance loops.
Conclusion and Next Steps
So are we done? Well yes, and no. There is still delivery semantics of the connector to talk about, getting out more performance, and optimizing infrastructure costs to run.
The next part of this series will talk about bringing more efficacy and performance from the same Connect infrastructure.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Streaming Platform at Adobe
- Kafka Connect dead letter settings — https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues
- Retriable exception — https://kafka.apache.org/10/javadoc/org/apache/kafka/connect/errors/RetriableException.html)
- Kafka Connect Rest APIs https://docs.confluent.io/current/connect/references/restapi.html#put--connector-plugins-(string-name)-config-validate
- Kafka Connect Transformations — https://docs.confluent.io/current/connect/transforms/index.html).
- JSON Patch Library https://github.com/flipkart-incubator/zjsonpatch
- Kafka Connect Metrics — https://cwiki.apache.org/confluence/display/KAFKA/KIP-196%3A+Add+metrics+to+Kafka+Connect+framework
- Kafka Connect Encryption — https://docs.confluent.io/current/kafka/encryption.html#encryption-ssl-connect
- Kafka Connect Authentication — https://docs.confluent.io/current/kafka/authentication_sasl/authentication_sasl_plain.html#sasl-plain-connect-workers
- Kafka Connect Authentication for brokers — https://docs.confluent.io/current/kafka/authentication_sasl/authentication_sasl_oauth.html
- Connect Rest extension — https://kafka.apache.org/20/javadoc/org/apache/kafka/connect/rest/ConnectRestExtension.html
- Externailzing secrets — https://cwiki.apache.org/confluence/display/KAFKA/KIP-297%3A+Externalizing+Secrets+for+Connect+Configurations
Originally published: Aug 13, 2020