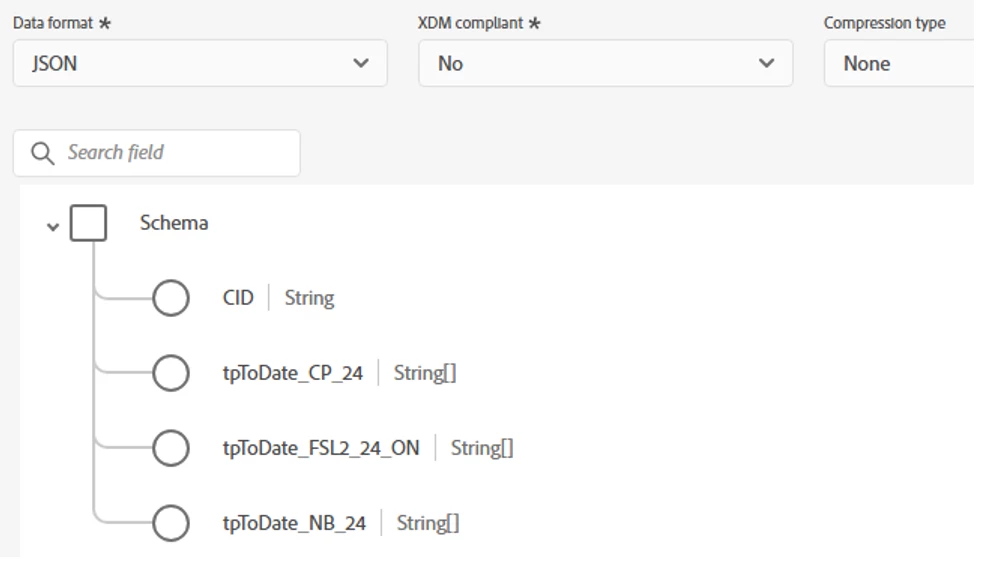
JSON file doesn't show all fields based on preview
I am trying to load some data to populate String[] arrays in and AEP dataset.
Here is my schema with 3 array String fields like below:
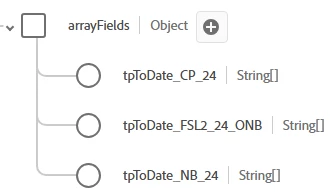
I prepped a JSON file to load some data in a dataset based on this schema. For the same customer ID - one, two or all three of these fields might be populated. Most of the time they are only one or two populated for one individual, but occasionally all three are.
The file I am trying to load has value on all 3 of these fields on some record or another. However, when I am trying to load the file, I only see two of these fields when it comes to mapping, like this for example:
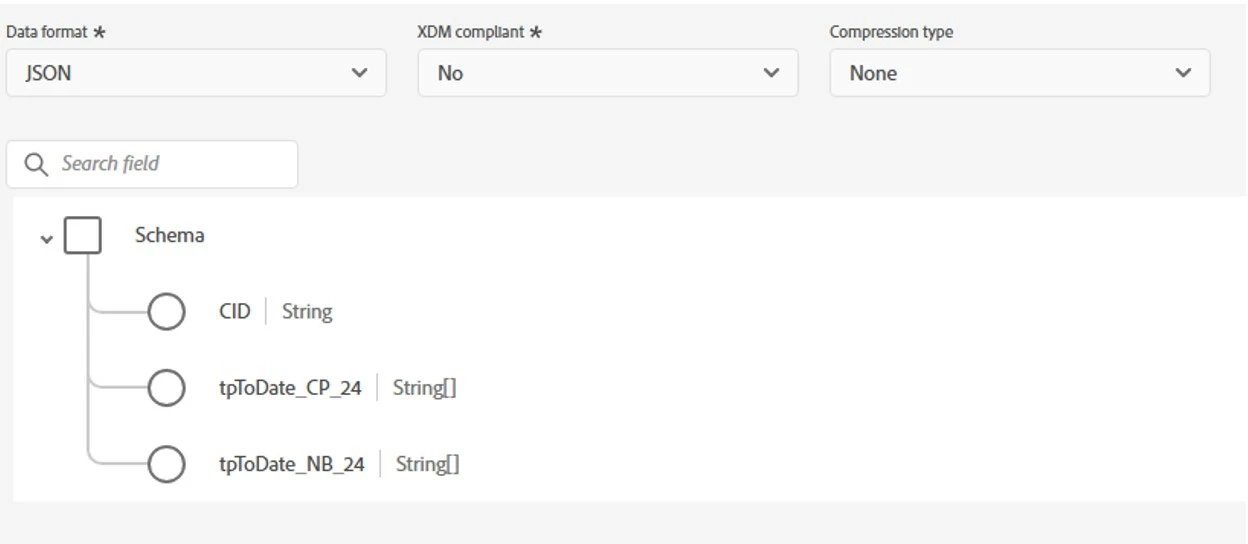
I believe that is because the preview on the file is looking at the first 10 rows or so, and in the first 10 rows only these two arrays are present. The third is also present somewhere in the file, but not in what the preview show.
---
I tried to force the mapping using a mapping file like below:

But with this mapping I get this error:


How can I map all three fields from file to schema, so all values are loaded? I hope I don’t have to export a separate file for each JSON field I have to ingest!
FYI: with a different row distribution in the file, where the first 10 rows have all 3 fields populated in one or more rows, all three array fields are available for mapping: