Abstract
This tutorial explains how to enable case insensitive search in AEM with Lucene.
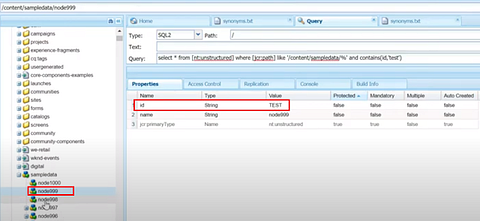
I have two nodes with property “id” under /content/sampledata with same value in different case e.g TEST and test
Analyzer
Analysis, in Lucene, is the process of converting field text into its most fundamental indexed representation, terms. These terms are used to determine what documents match a query during searching.
An analyzer tokenizes text by performing any number of operations on it, which could include extracting words, discarding punctuation, removing accents from characters, lowercasing (also called normalizing), removing common words, reducing words to a root form (stemming), or changing words into the basic form (lemmatization).
Configure Analyzer
The analyzers is configured via the analyzers node (of type nt:unstructured) inside the oak:index definition.
The default analyzer for an index is configured in the default child of the analyzer’s node(of type nt:unstructured).
Create a child node with name “tokenizer” of type “nt:untstrutured” under default node and add the property “name” with value “Standard”
Read Full Blog
Q&A
Please use this thread to ask the related questions.
Kautuk Sahni







