Facing Issues for Robots.txt in AEM Cloud SDK
Dear All,
I have setup AEM cloud SDK in my local and trying to implement robots.txt by following the below blog.
https://www.aemtutorial.info/2020/07/
Here I am facing 2 issues.
1) Issue-1 - I have created a file under root content like below.
/content/mysite/robots.txt
When I am trying to see the robots.txt from the page in author/publish like http://localhost:4503/content/mysite/robots.txt , then robots.txt is downloading...
2) Issue-2 - When I am hitting the robots.txt from the dispatcher page then also I am not seeing the any content frrom robots.txt , as shown below.
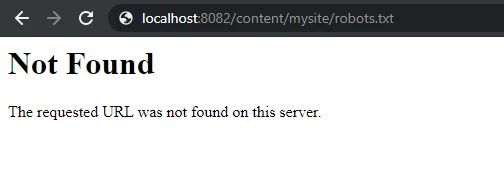
I am getting below error log in dispatcher it is showing that blocked [publishfarm/-] 0ms "localhost:8082".
[27/May/2021:08:39:31 +0000] "GET /content/dam/mysite/robots.txt HTTP/1.1" - blocked [publishfarm/-] 0ms "localhost:8082"
172.17.0.1 "localhost:8082" - [27/May/2021:08:39:31 +0000] "GET /content/dam/mysite/robots.txt HTTP/1.1" 404 196 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
172.17.0.1 "localhost:8082" - [27/May/2021:08:40:25 +0000] "GET /content/mysite/robots.txt HTTP/1.1" 404 196 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
[27/May/2021:08:40:25 +0000] "GET /content/mysite/robots.txt HTTP/1.1" - blocked [publishfarm/-] 0ms "localhost:8082"
My robots.txt file is below
#Any search crawler can crawl our site
User-agent: *
#Allow only below mentioned paths
Allow: /en/
Allow: /fr/
Allow: /gb/
Allow: /in/
#Disallow everything else
Disallow: /
Can anybody please help me on this. Thanks a lot....NOTE that I am using AEM cloud SDK in my local.