To improve the situation effectively, consider exploring following options.
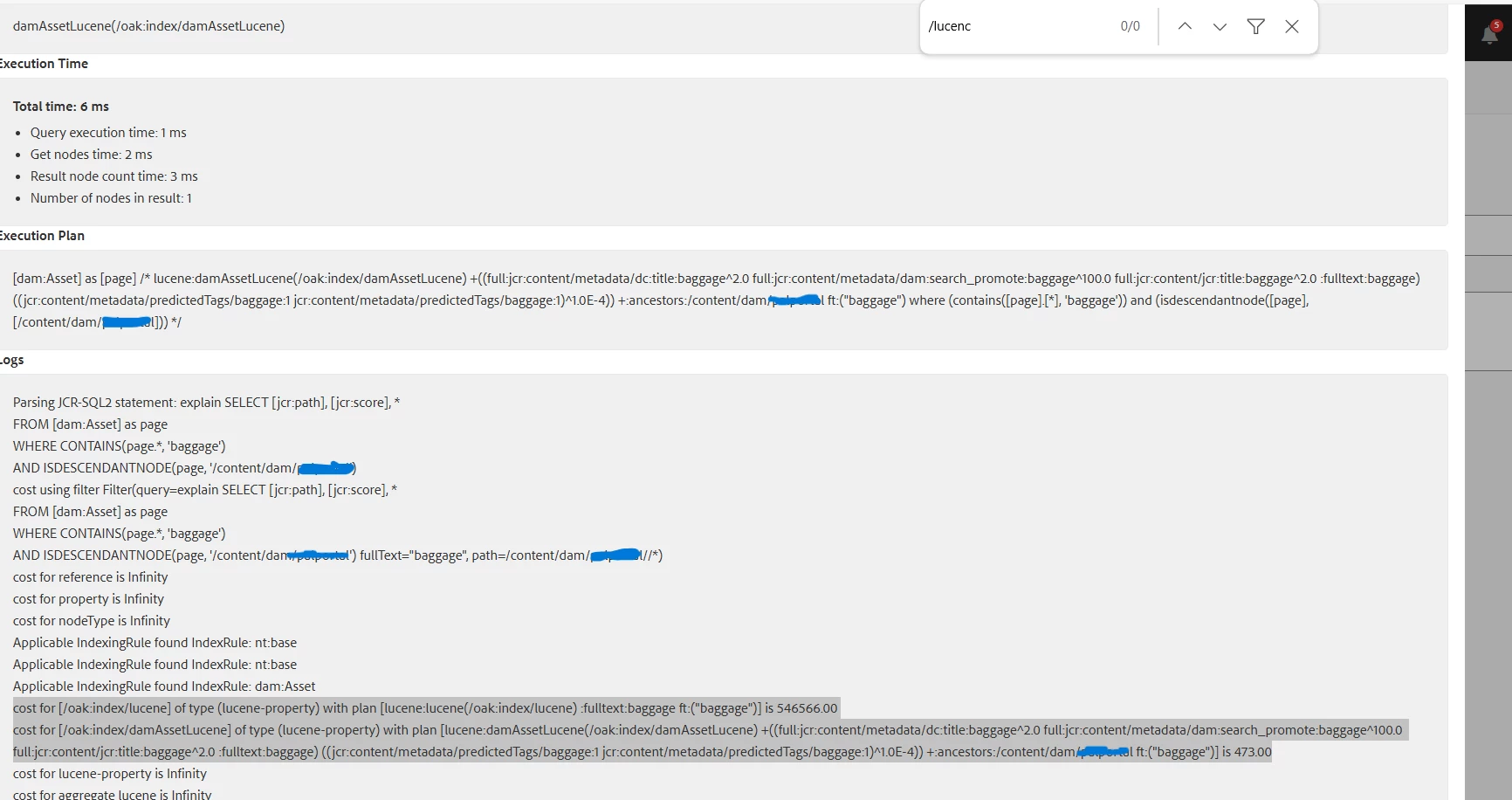
- The queryPerformance.html tool indicates the /oak:index/lucene index has a cost of 546,566 , which is significantly higher than the DAM-specific index (damAssetLucene). This suggests that the query is triggering a full-text search across the entire repository via the generic Lucene index. The group.p.or=true condition combines two groups (pages and DAM assets), forcing the query to scan multiple paths.
- Setting p.limit=-1 fetches all results , which is resource-intensive. Use pagination (e.g., p.limit=20&p.offset=0) to reduce load.
- If pagination isn’t feasible, ensure the query is as restrictive as possible.
- You can restructure the query by split the query into two separate queries:
For pages (cq:PageContent):
fulltext=baggage
path=/content/project1/ph/en/home
type=cq:PageContent
For DAM assets (exclude JSON files):
fulltext=baggage
path=/content/dam/project1
type=dam:Asset
property=jcr:content/metadata/@dc:format
property.value!=application/json
This ensures the DAM-specific index (damAssetLucene) is used exclusively for assets, avoiding the costly generic Lucene index.
- You can also define a custom Lucene index for /content/project1 pages to avoid full-repository scans. Example oak:index definition:
<index name="customPageLucene" type="lucene">
<property name="path" value="/content/project1"/>
<property name="type" value="cq:PageContent"/>
<property name="includePropertyTypes">
<value>metadata/@dc:format</value>
<value>jcr:title</value>
</property>
</index>
This will ensure the query targets a specific index instead of the generic one.
Further reading:
Query and Indexing Best Practices
Troubleshooting Slow Queries