Hi @_manish_singh,
Thank you for your question! Can I ask: is there a reason that you are using a word document to store HTML code?
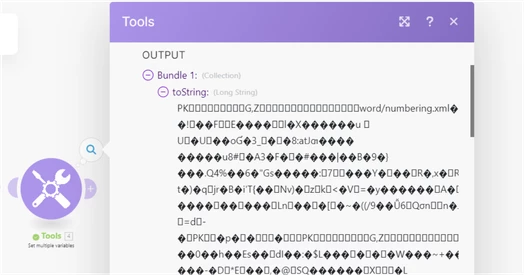
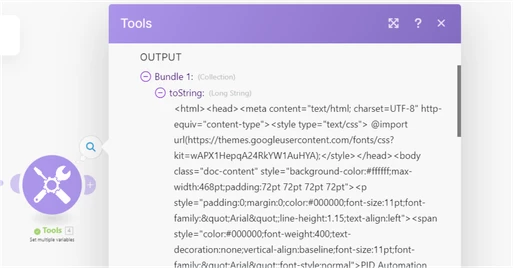
I ask because the Download Document module for Workfront only outputs the raw data available; this is the strange string with lots of unreadable characters. The module is meant to retrieve the document and serve as an aid to move it from Workfront into another application (for example, move a document from Workfront into Google Drive). The module is not meant to be retrieved from Workfront and then read in Fusion.
https://experienceleague.adobe.com/en/docs/workfront-fusion/using/references/apps-and-their-modules/adobe-connectors/workfront-modules#:~:text=The%20module%20returns%20the%20document%E2%80%99s%20content%2C%20filename%2C%20file%20extension%2C%20and%20file%20size.%20You%20can%20map%20this%20information%20in%20subsequent%20modules%20in%20the%20scenario.
If what you're trying to achieve is simply to get HTML code into Fusion, there are other options available:
1) Hard code the HTML into Fusion through the use of a Create Variable module.
or
2) If the HTML code is coming from users who submit this word document, you could setup a request queue with a field for the HTML code. Then use Fusion to read the contents of the custom field and do something with it.
or
3) Upload that HTML to GitHub and then call GitHub's API to output it.
If you'd like to see this functionality implemented into Fusion in the future, I would recommend submitting a feature idea to our innovation lab.
https://experienceleague.adobe.com/en/docs/workfront/using/basics/tips-tricks-for-basics/idea-exchange
- Monica