
Adobe Customer Journey Management’s Journey into the World of GitOps
Authors: Seung Kim and Marco Massenzio

The topic of CI (Continuous Integration) and CD (Continuous Deployment) is one of the most hotly debated across organizations and development communities. CI/CDs have many different solutions to, and opinions by, organizations, developers, and communities.
By and large, however, everyone agrees that at a minimum, a CI/CD framework should provide:
- Orchestrated code-to-deployment process
- Monitoring and alerting
- Log management
- Reporting
This blog details Adobe Customer Journey Management (CJM) CI/CD discovery, architecture, and our learnings.
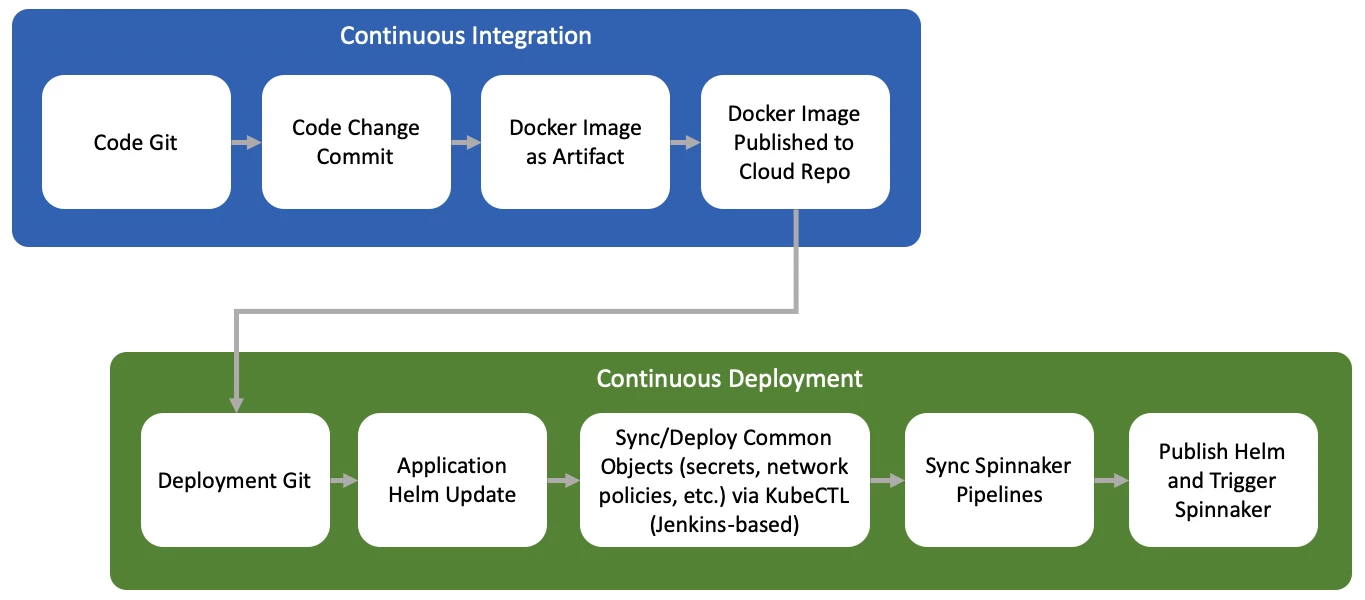
Adobe Customer Journey Management (CJM) CI/CD Overview
Adobe’s Customer Journey Management (CJM) is designed from the ground-up, to be a cloud-native and container-based multi-tenant system. We have chosen Kubernetes as our execution environment, as it is well-supported within Adobe. That decision was motivated by the following considerations:
- Kubernetes allows developers to focus on logical entities, such as services, pods, and stateful services while abstracting from hardware details and Cloud provider specifics.
- We could take advantage of Kubernetes native APIs and Objects (Horizontal Pod Autoscaler, for example) and avoid having to re-implement them.
- Container Images as the immutable deployment artifacts.
Consistency across services, when managing the build artifacts, and launching applications, was a requirement.
Thus, the requirements of our Adobe CJM CI/CD can further be specified as:
- CI is responsible for handling the process of creating well-defined and well-tested deployment artifacts (Docker Images) and all necessary configurations, resources, and states specific to an application version are embedded in the docker image.
- CD is responsible for handling the process of exposing the artifacts as services, by defining a set of commonly used objects and steps and treating the deployment process as an “artifact”.
- Runtime specific needs (such as logs gathering/forwarding; metrics; and common services such as caching) are to be handled by the CD framework.
Further, CI/CD process must guarantee correctness at every step in the code-to-artifact pipeline and that all validations are correctly evaluated (e.g. tests pass without failures) during the process of promoting the artifact from Development to Stage to Production.
Beyond the functional requirements, we also desire the build and deployment process to be as cheap and repeatable as possible. Here “cheap” really means what it says, as we use Public Cloud resources, and any efficiency gain is reflected in actual financial savings.
Requirements and Architectural Principles
We architected the system following the principle of “Separation of Concerns” so that the responsibilities are split accordingly:
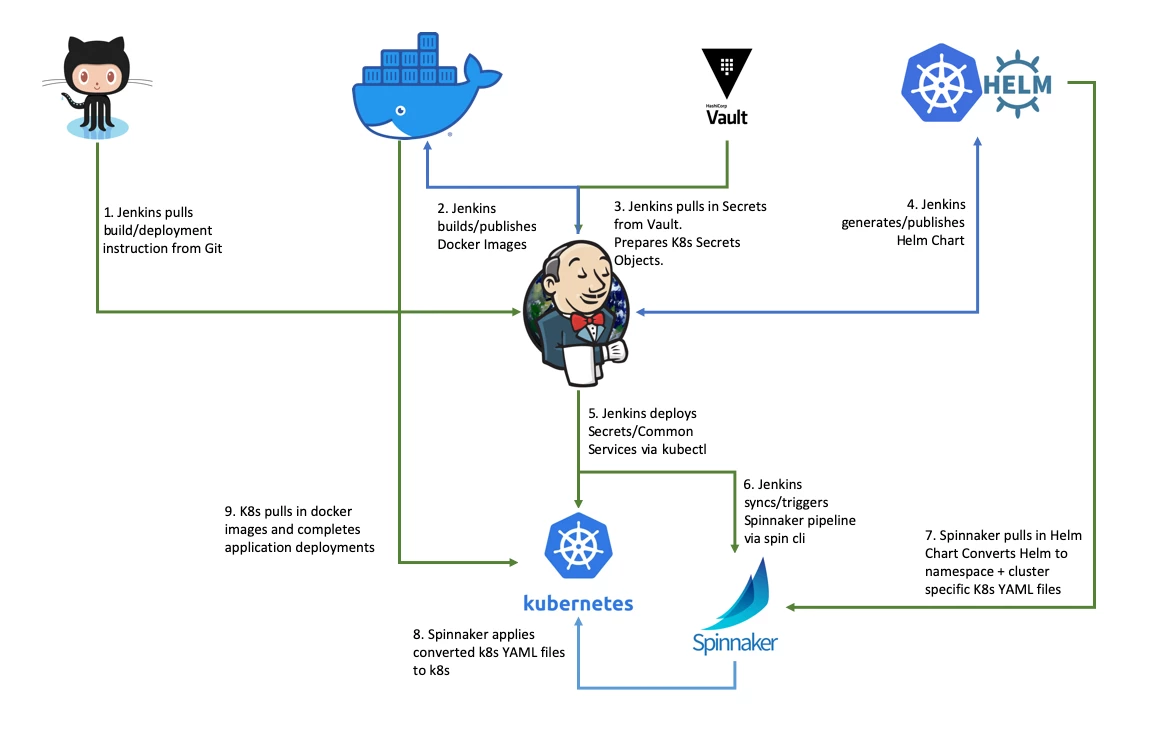
- Jenkins, to build and test the artifact, produce the container image
- Spinnaker to manage and orchestrate the artifact deployment
- Kubernetes to manage the runtime environment
However, the design is such that, if required, each component could be substituted for an equivalent one. For example, we experimented with using CircleCI as our build/test toolchain.
After running some prototypes, the team realized the following:
- Kubernetes is useful but has a steep learning curve, so it may be beneficial to provide frequently used operations as a set of features in the CD process.
- Kubernetes CLI (kubectl) can be challenging to use for complex deployment orchestration, such as red/black deployment. So, we went along with an industry-proven CD orchestrator: Spinnaker.
- Spinnaker also has a steep learning curve, especially the pipeline generation and management.
- Following the GitOps model, the entire process should be managed via git commits and operations:
a. No more divergent and scattered information among git, spinnaker, Kubernetes, and any other related systems.
— All information always flows from Git. Everything else is derivative of git.
b. No manual intervention for deployment
— No manual changes via Spinnaker UI
— No changes via kubectl CLI commands
c. This also includes multi-region deployments, handled via git commands.
Our original visions, which we have achieved, are:
- Git as the source of truth, for code and deployment
- Allow consistent access pattern for managing/handling artifacts
- HashiCorp Vault for secrets management
- Jenkins to manage common Services/Objects deployment in Kubernetes
- Provide easy Helm chart generation via CJM templating engine
- Provide easy integration with Spinnaker
Our Learnings
Git as the source of truth, for code and deployment
Traditionally, coding has been handled by software engineers. Build and release was the realm of dedicated QA and Release engineers. This separation of concerns has led to divergent practices for the management of code and deployment scripts, and often to territorial ownerships between the various teams. Understanding and managing scripts and processes takes time and effort.
By extending what had become known as “Infrastructure as Code” to the area of build/release/deploy and codifying the necessary steps, as well as using git not only as of the sole source of truth but also as the common lingua franca across domains, the GitOps model aims to remove such barriers and contribute to a more open development environment.
Allow consistent access patterns for managing artifacts
Managing artifacts consistently (“convention over configuration”) allows us to address many concerns implicitly:
- How to ensure all artifacts can be treated in a consistent manner at the time of deployment
- How to track changes applied to a particular docker image version
- How to promote built artifacts (docker images) to eventually running pods in Kubernetes
Our approach to CI/CD promotes the following conventions:
- Docker images as CI artifacts and use of a common “base” Docker image provides consistent app-specific runtime within docker-ecosystem;
- Kubernetes objects, managed in Helm chart format, as CD artifacts;
- Artifacts published to a centralized (secure, private) repository;
- Artifacts versioned using the 10-digit git hash of the commit (SHA) at the time of the build in the code git repository so that all changes made into building a particular artifact can be easily traced back
HashiCorp Vault for secrets management
Secrets are necessary to interact with certain systems and services: they may be needed for Jenkins-based integration tests, and will most definitely be needed at deployment time.
However, entering them manually every time would be impractical (and would entirely break the premise behind CD) or, possibly worse, storing them along with the source code in a git repository is an absolute security no-no.
We chose to make secrets management declarative, instead.
- HashCorp Vault manages runtime secrets
- Git maintains a mapper file
- During deployment, Jenkins pulls in secrets from Vault, based on the mapper file instructions, and deploys retrieved data from Vault as Kubernetes Secrets objects
Having only declarations stored in Git, CJM safely separates and maintains valid secrets data stored in Vault, and ensures always up-to-date secrets are published to Kubernetes.
Use Jenkins for managing Common Services/Objects in Kubernetes
CJM utilizes Jenkins as a means of managing common services and secrets.
As many common services are stateful, such as Prometheus and MemcacheD, we can safely maintain valid service states via rolling deployments. This approach allows service upgrade without interruption, while not having to worry about traffic management issues, which are transparently handled by Spinnaker.
Equally for Kubernetes Secrets, unlike app-specific configuration maps, secrets hardly require versioning. We just want what is in Vault to be presented in a consistent manner to our deployment environment.
Jenkins in this manner lays down the foundational dependencies for eventual application deployments.
Provide easy Helm chart generation via our templating engine
In a typical REST application deployment, we need the following features/objects.
- FQDN (fully qualified domain name) and URI mapping
- Load Balancer/traffic management to application pod(s)
- Managing elasticity for pods
- Log forwarder, via Fluent-bit sidecar
Since these features are app-specific, they must be bundled in the application Helm chart. Most of these declarations are commonly reusable features. Copying/pasting YAML files lead to inconsistency and are highly prone to error; not to mention, any subsequent changes/additions need to be replicated (manually) across several code repositories, adding to the opportunity for errors, misconfiguration, and out-of-sync content causing issues during deployment (or, worse in Production).
Instead, we opted for the following:
- Create commonly used features as injectable YAML template files.
- App’s Helm Charts reference these template files as dependencies.
- During Helm chart publishing time, the deployment step will generate full Helm charts based on template dependency instructions.
- The end result is a fully-formed Helm Chart
Ultimately, developers only need to focus on providing the following.
- docker-image and tag
- healthCheck URL
- Application specific thresholds
All other information, such as ImagePullSecret, common Environment variables, and network policy are hidden away from the developer’s view.
Provide easy integration with Spinnaker
Spinnaker has many great features when it comes to deploying applications. Managing traffics during an upgrade is a good example. However, building Spinnaker pipelines can be challenging, as it requires detailed domain knowledge.
Also, pipelines can be easily modified via UI, which are impossible to track, and hard to replicate (typically by providing screenshots and documentation, which quickly gets stale and is hard to maintain); further, any accidental change can cause major consequences. Spinnaker’s limited change management functionality does not help much in this respect.
Others copy and paste the generated Pipeline JSON into Git. However, the initial generation of pipeline is not declarative; someone needed to create them manually, and the flow of data originates from Spinnaker — not from Git.
And even if it worked (which it doesn’t), any time one sees a process requiring manual copy & paste, a healthy dose of skepticism is in order: it is almost universally a symptom of lazy thinking and poor (or non-existent) automation.
In Production, it is virtually assured to come back and cause significant system outage and customer disruption at one point or another, and usually at the most critical moment, when one can least afford it.
Instead, our CD solution defines a frequently used set of pipeline phases (fetch Helm Chart -> bake -> deploy) which is stored in Git: this allows app developers to define only deployment clusters and environments (equally stored in Git).
Spinnaker pipeline JSON files are then auto-generated during deployment time and pushed from Jenkins via Spin CLI.
The end result is that there is no need to manage Spinnaker pipelines via the UI directly; the latter is used mostly for debugging purposes, as a “read-only” control pane.
What’s Next
Adobe has a vast amount of different technologies and practices it has acquired over the years. Some are from individual contributors. Some are from acquisitions of existing teams/companies. Along with them, their unique culture and knowledge have combined into Adobe.
Our team’s CI/CD main goal is to provide a safe deployment environment, where the basic functionality “just works,” so that all applications onboarded on our large-scale distributed customer journey management solution can enjoy flexibility in development, and benefit from well-orchestrated CI/CD processes, to help developers understand where and how their applications are.
We believe this approach also has a positive side-effect in promoting the DevOps mindset and is rooted in the GitOps principles.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Adobe Customer Journey Management
- Kubernetes
- Spinnaker
- CircleCI
- Helm
- Jenkins
- Docker
- MemcacheD
- Prometheus
- HashiCorp Vault
Originally published: Oct 29, 2020