Hi,
Situation
So i have a ocr'd pdf like this(please look at the attachements), Now What im currently doing is, i manually converted the the ocr pdf to xml file. The pdf has around 350 pages, and converting everything at a time into xml is not keeping the format, so i had to do 2 pages convertion everytime.

I tried sdk but it doest have a pdf to xml convertion option(atleast whats available in the readme file).
Manually converted xml is nice and all but there some cases where its not taking the tables. Like below where it should have been a table but ended up a sub heading.
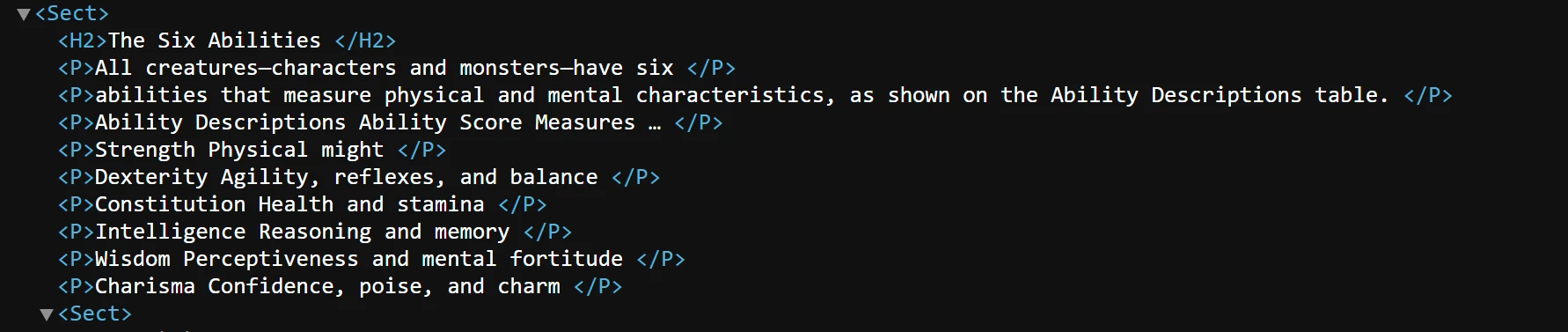
Needed output
The final i put i want is in the form of jsonl, converting pdf to xml is keeping the hierarchial structure including the tables, thats what i want.

What im currently doing
Currently i converted my pdf to json, which is keeping the structure, but needs a lot of parsing.
Im working not making a vector data base for my RAG model, and having perfectly formatted data is key. So thats the reason im going extreme lengths to keep the formating of the tables.
Hi @yaswanth_reddybh ,
What is the software being used for this conversion? Are you using AEM Forms product for this conversion? Or are you using Acrobat PDF Services APIs? Or automation written on top of Acrobat?
My guess is you are using Acrobat PDF Services APIs. You have posted this question on AEM Forms forums which is not the right place for this question.
Regards,
Sufyan