Solved
Adobe Analytics Segment Matches Operator
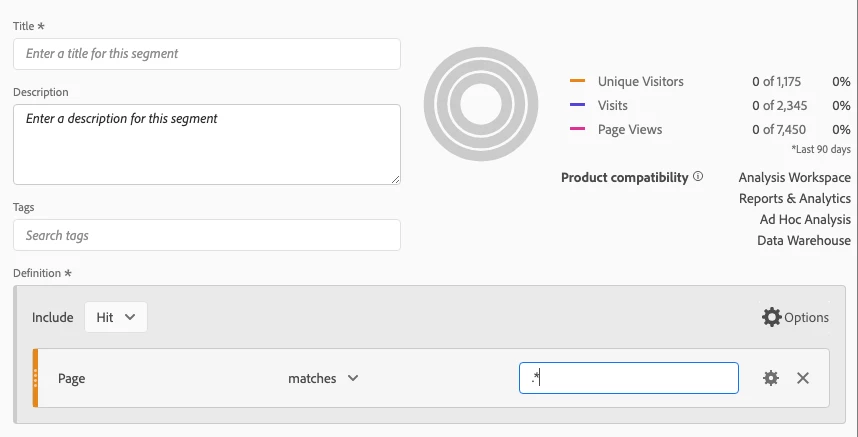
I was wondering if someone knows the exact regex capabilities support by the "matches" operator from the segment builder.
Per documentation:
Comparison Operators for Segments | Adobe Analytics
| matches | Returns items that match exactly based on a given numeric or string value. The “matches” clause is case sensitive in Adobe Analytics and in Customer Journey Analytics. Note: Use this operator when using wildcard (globbing) features. Examples of “globbing”:
|
At the moment I am using Adobe Classification Rule Builder to create Buckets of value for specific dimensions that contains numeric values. I would like to use the same regex functionality as in Classification Rule Builder to create segments based on same regex formulas.
Per the documentation is seems to support regex wildcard character only.
This is the kind of regex I would like to use:
^.*rFundA=((?!20000)(2\d\d\d\d)|30000)\.?[0-9]*\|.*$