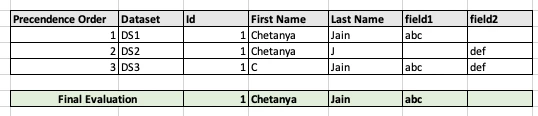
@luca_lattarini @chetanyajain-1 When you say "no preference", I want to make sure I understand... In the test you did you are saying field 2 ended up being?
- [field doesn't exist on profile]
- "def"
Also, just wanted to make sure you loaded the data in the order laid out in the example.
Thanks for testing this.
BTW, I so rarely use this because of a few reasons, but good to know how it works.
Hi Danny,
The testing was done in the order it was laid out in the example Chetanya had put together.
In AEP, we only have 2 options/ways to define the construction of profile unification:
- Tiimestamp based
- Dataset precedence
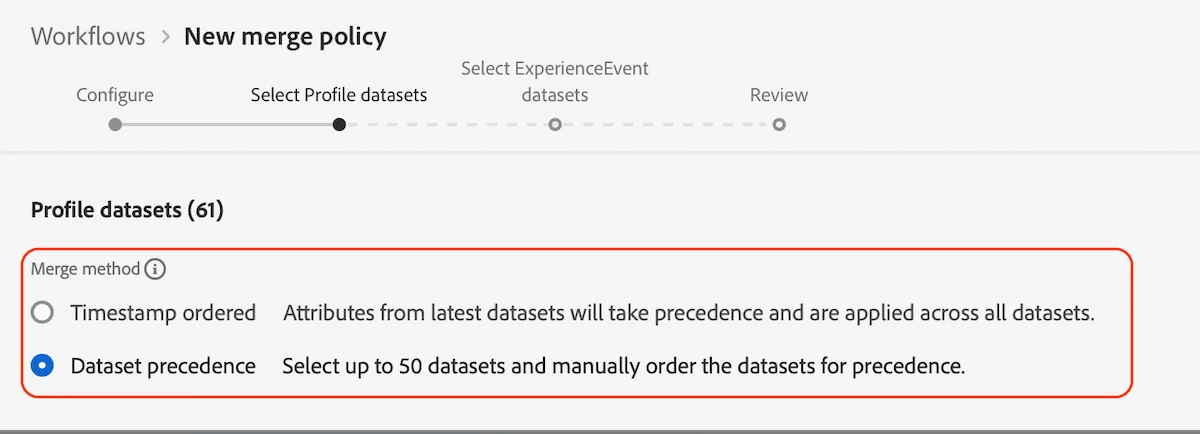
In this testing, based on the selected merge policy (Dataset precedence), the Dataset 1 wins (as it has highest precedence). As, in Dataset 1, "field 2" is NULL, the unified profile will not have this "field 2". This is how "Dataset precedence" works.
What I understood from this thread is - Luca is looking for an additional Option ("Data Completeness") - if my winning dataset does not have any value to a particular field and other loosing datasets are having values for that field, then the populated value needs to be selected from the next lower precedent dataset.
This is a very common Data survivorship functionality of Master Data Management.
@luca_lattarini ,
I second @danny-miller's thought, I also rarely use or plan to use "Dataset precedence". If I decide to use this, I would perform a deep level analysis to understand why I really need this.
From my own perspective - this is a core MDM problem and MDM is solving this for more than a decade. This should be handled outside AEP, must be in MDM or in ETL layer (if no MDM is available and you have this requirement). We need to understand the sole purpose of CDP - what it is meant to solve - we should not consider CDP as a magic box.
If we start solving all the data problems in CDP, then it will loose the feasibility - #tradeoff.
My perspective may be wrong from others point of view and I am always open to discuss on this.