Solved
Failed records(batch ingestion) due to MaxIdentities and InvalidXdm error
Hi,
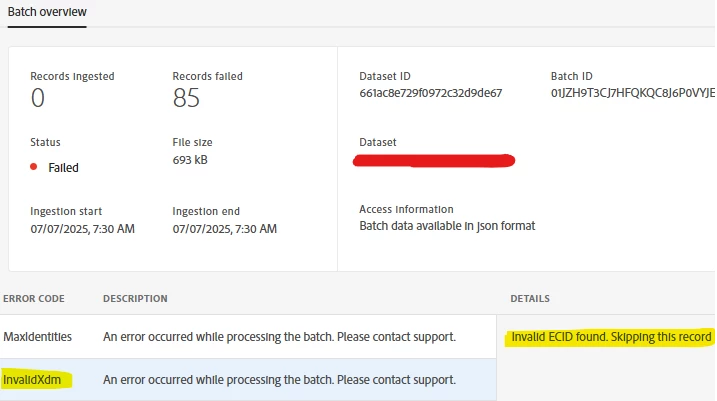
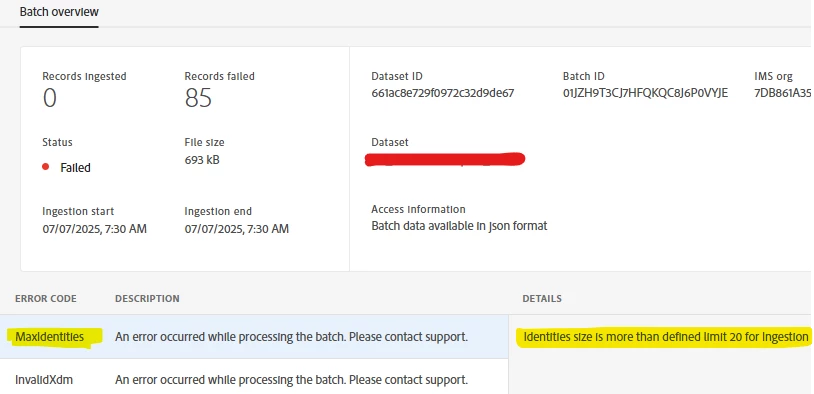
There are few records which have failed to ingest (to a dataset having batch ingestion) due to MaxIdentities error and InvalidXdm error. For MaxIdentities it says "Identities size is more than defined limit 20 for Ingestion" and for InvalidXdm it says "Invalid ECID found. Skipping this record".
Could someone please help me understand what does the MaxIdentities error mean? And if there is any way to stop these records from failing?
Thanks,
Sambit