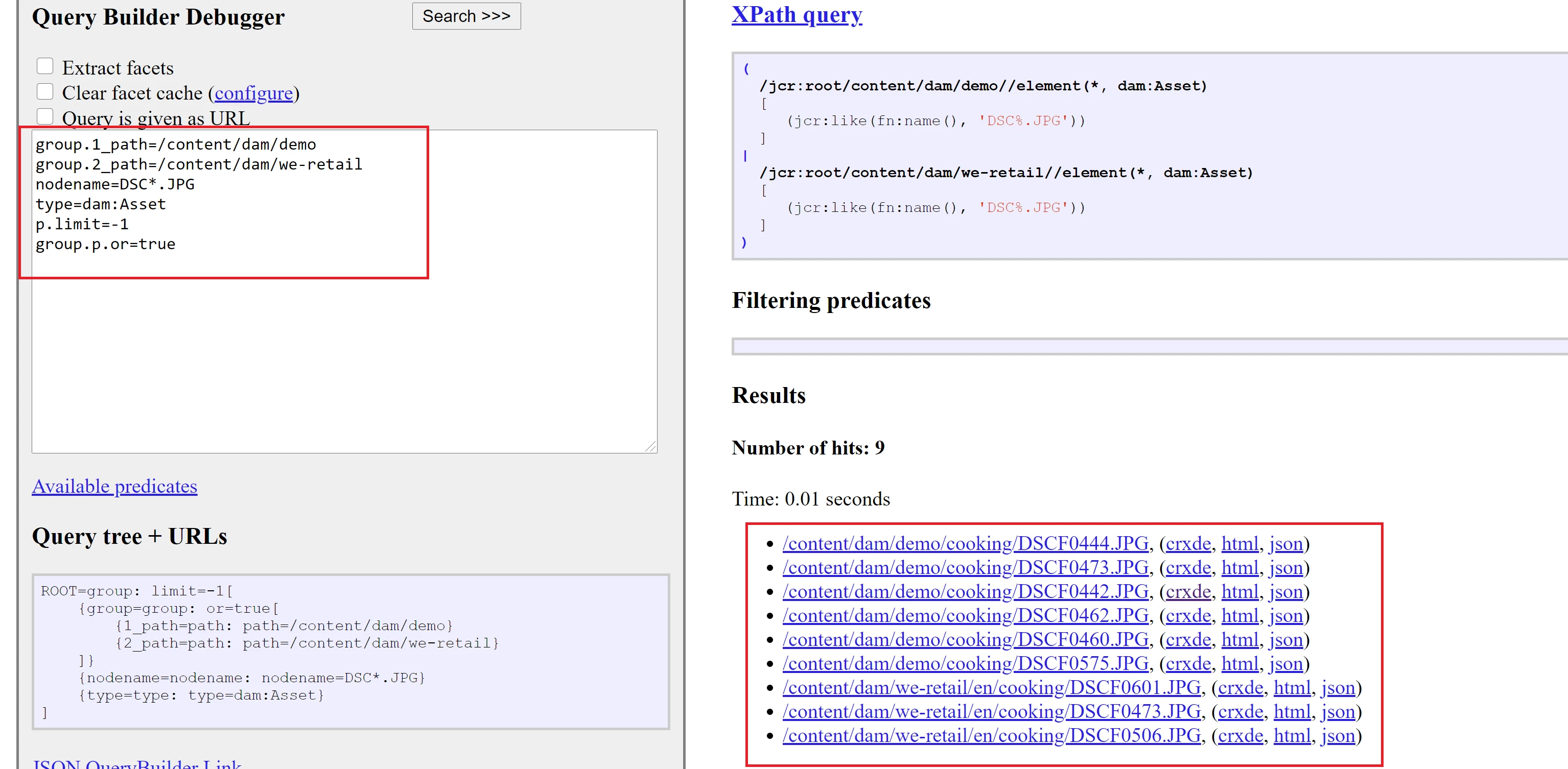
Identify image-based (scanned) pdfs in the DAM?
Hi,
Hoping there might be a way to identify pdfs (we have almost 20,000 in the DAM in a number of folders) that are image-based (scanned)....usually created when the owner could not locate the original digital copy and ended up just scanning a paper copy and creating a pdf. Over the years, we ended up with hundreds of these.
I thought maybe a very simple solution would work - in site admin>aem assets and using the search, with "-the" in fulltext, and file type=pdf (the idea being that since the pdfs are image based, there would not be any text to find and "the" is a pretty common word). This actually does find some but also end up with lots of "false positives".
Would there be a way of doing this via coding/programming (not something I can do but can pass on to our programmer) or even an "advanced search query"?
Jerry